文章目录
- 相关论文
- 相关资料
- 摘要
- 引言
- 方法
- 对视觉 token 的特征融合
- 使用注意力偏差进行掩码识别
- 分割图像生成
- 实验
相关论文
(CVPR,2024)SED:一个用于开放词汇语义分割的简单编解码器
(CVPR,2024)CAT-Seg:基于成本聚合的开放词汇语义分割
(CVPR,2023)SAN:用于开放词汇语义分割的边缘适配网络
(ISPRS,2023)深度语义-视觉对齐用于zero-shot遥感图像场景分类
(CVPR,2022)ZegFormer:基于解耦的zero-shot语义分割
(CVPR,2023)PADing:通用zero-shot分割的基元生成与语义对齐
(CVPR,2023)ZegCLIP: 使用CLIP进行单阶段零样本语义分割
(NeurIPS,2019)【代码复现】Zero-Shot Semantic Segmentation零样本语义分割
相关资料
论文:Side Adapter Network for Open-Vocabulary Semantic Segmentation
代码:https://github.com/MendelXu/SAN
摘要

本文提出了一种新的开放词汇语义分割框架,名为边缘适配器网络(SAN)。我们的方法将语义分割任务建模为区域识别问题。一个边缘网络附加到一个冻结的CLIP模型上,具有两个分支:一个用于预测掩模提案,另一个用于预测注意偏差,该偏差应用于CLIP模型中以识别掩模的类别。这种解耦的设计使得CLIP在识别掩模提案的类别时受益良多。
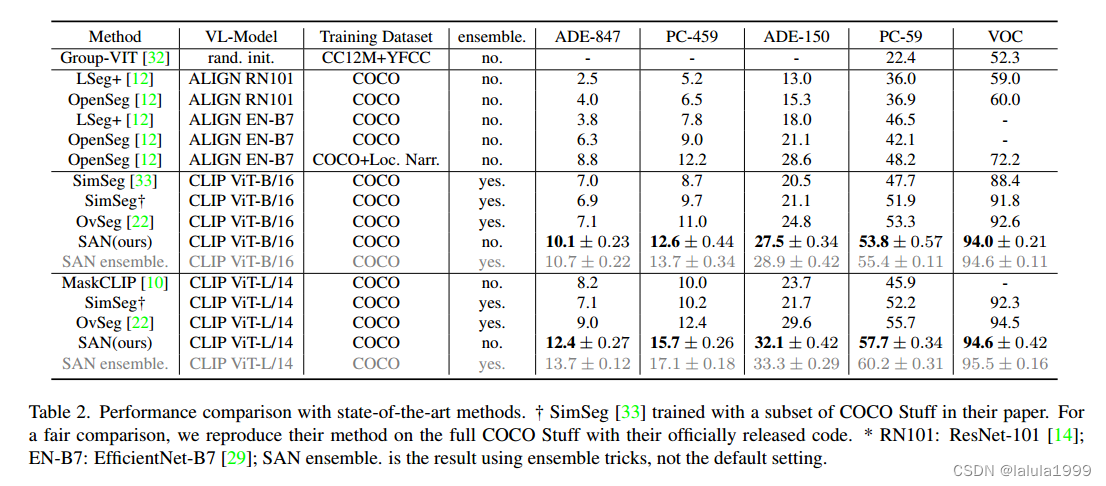
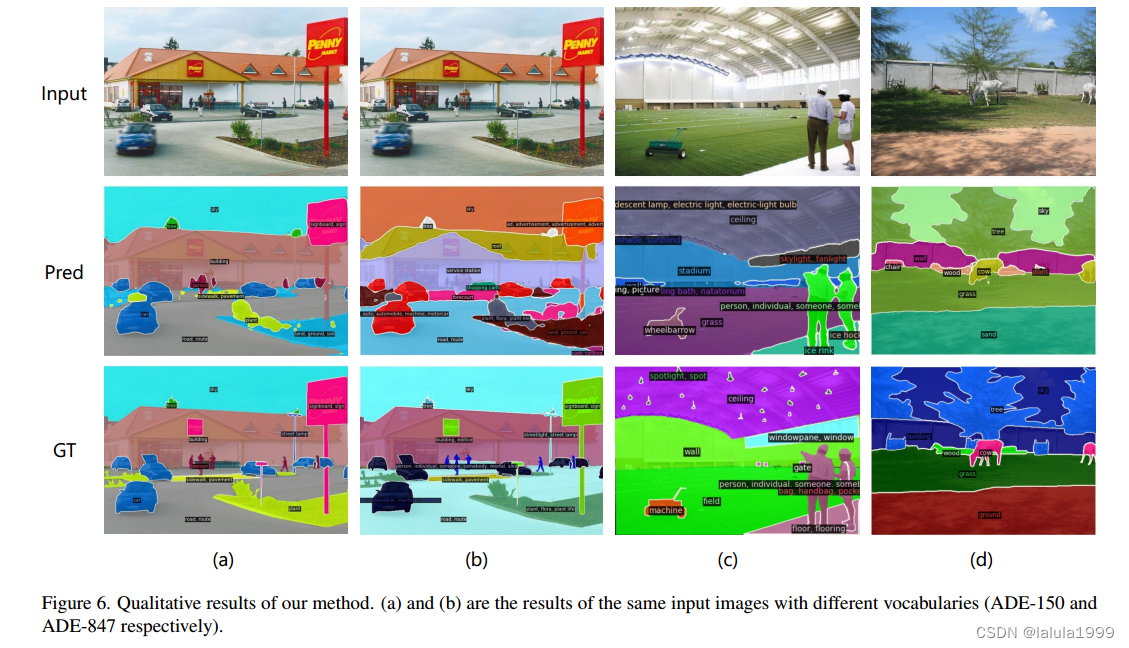
由于附加的边缘网络可以重用CLIP特征,因此可以非常轻量级。此外,整个网络可以进行端到端的训练,允许边缘网络适应冻结的CLIP模型,从而使得预测的掩模提案具有CLIP感知能力。我们的方法快速、准确,并且仅添加了少量的可训练参数。我们在多个语义分割基准数据集上评估了我们的方法。我们的方法显著优于其他对比方法,可训练参数数量少达18倍,推断速度快达19倍。图1展示了在ImageNet上的一些可视化结果。我们希望我们的方法能够作为一个坚实的基线,并帮助简化未来在开放词汇语义分割方面的研究。
引言
识别和分割任何类别的视觉元素是语义分割的追求。现代语义分割方法依赖于大量标记数据,但通常数据集往往只包含数十到数百个类别,昂贵的数据收集和注释限制了我们进一步扩展类别的可能性。最近,代表性的大规模视觉语言模型,如CLIP,使得在图像级别进行任意类别识别成为可能,即开放词汇的图像分类,这一巨大成功鼓励我们探索其在语义分割中的应用。
将CLIP模型应用于开放词汇的语义分割是具有挑战性的,因为CLIP模型是通过图像级对比学习进行训练的。它学习的表示缺乏语义分割所需的像素级别的识别能力。解决表示粒度差异的一种解决方案是在分割数据集上对模型进行微调。然而,分割数据集的数据规模远远小于视觉语言预训练数据集,因此微调模型在开放词汇识别上的能力经常受到影响。
将语义分割建模为区域识别问题可以避开以上困难。早期尝试采用了两阶段训练框架。在第一阶段,一个独立模型被训练以生成一组被掩码的图像裁剪作为掩码提议。在第二阶段,使用视觉语言预训练模型(例如CLIP)来识别掩码图像裁剪的类别。然而,由于掩码预测模型完全独立于视觉语言预训练模型,它错过了利用视觉语言预训练模型的强特征的机会,而且预测的掩码图像裁剪可能不适合识别,这导致了一个笨重、缓慢且性能低下的模型。
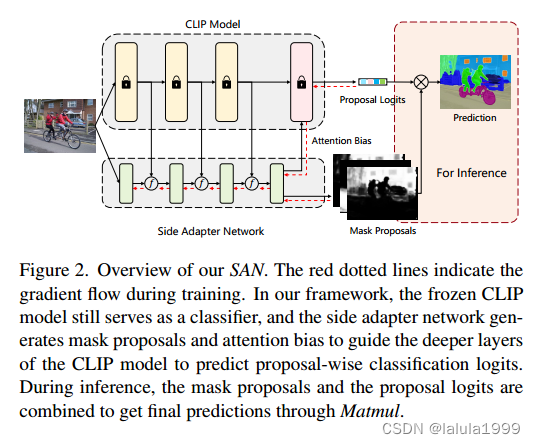
本文旨在充分发挥视觉语言预训练模型在开放词汇语义分割中的能力。为了实现这一目标,我们提出了一个新的框架(图2),称为辅助适配器网络(SAN)。由于端到端训练,其掩码预测和识别都是CLIP感知的,并且由于利用了CLIP的特征,它可以是轻量级的。
辅助适配器网络有两个分支:一个预测掩码提议,一个预测应用于CLIP的自注意力块的注意力偏置以进行掩码类别识别。我们展示了这种解耦设计提高了分割性能,因为CLIP用于识别掩码的区域可能与掩码区域本身不同。为了最小化CLIP的成本,我们进一步提出了单次前向设计:浅层CLIP块的特征被融合到SAN中,其他更深层的块与注意力偏置结合以进行掩码识别。由于训练是端到端的,因此辅助适配器网络可以最大程度地适应冻结的CLIP模型。
准确的语义分割需要高分辨率的图像,但发布的ViT CLIP模型设计用于低分辨率图像(例如224×224),直接应用于高分辨率图像会导致性能下降。为了缓解输入分辨率的冲突,我们在CLIP模型中使用低分辨率图像,在辅助适配器网络中使用高分辨率图像。我们展示了这种不对称的输入分辨率非常有效。此外,我们还探索了仅对ViT模型的位置嵌入进行微调,并注意到了改进。
方法
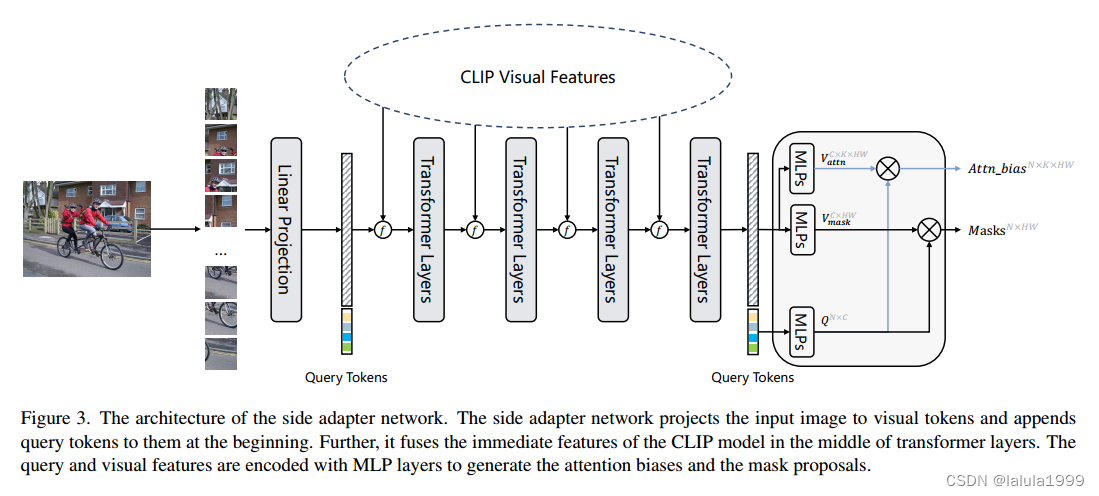
SAN 是由一个轻量级的ViT实现的,可以利用 CLIP 的特征,它有两种输出:掩码提议和注意力偏差。注意力偏差被应用于 CLIP 的自注意力,用于识别掩码提议的类别。 实际中,我们将浅层 CLIP 层的特征融合到 SAN 中,并将注意力偏差应用于更深层的 CLIP 层进行识别,从而最小化 CLIP 模型的成本。
SAN 的详细架构如图 3 所示。输入图像被分割成 16×16 个 patch,并应用线性嵌入层将其投影为视觉 token。这些视觉 token 然后与 N 个可学习的查询 token 连接在一起,输入到后续的Transformer层。我们在每个Transformer块中为视觉 token 和查询 token 添加绝对位置嵌入。位置嵌入在各层间共享。
在掩码预测中,查询 token 和视觉 token 首先通过两个独立的 3 层 MLP 投影为 256 维,我们将投影的查询 token 表示为
Q
m
a
s
k
∈
R
N
×
256
Q_{mask}∈ℝ^{N×256}
Qmask∈RN×256,其中 N 是查询 token 的数量,将投影的视觉 token 表示为
V
m
a
s
k
∈
R
H
/
16
×
W
/
16
×
256
V_{mask}∈ℝ^{H/16×W/16×256}
Vmask∈RH/16×W/16×256,其中 H 和 W 是输入图像的高度和宽度。然后,掩码通过
Q
m
a
s
k
Q_{mask}
Qmask和
V
m
a
s
k
V_{mask}
Vmask 的内积生成:
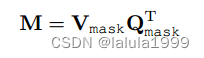
其中
M
∈
R
H
/
16
×
W
/
16
×
N
M∈ℝ^{H/16×W/16×N}
M∈RH/16×W/16×N。生成注意力偏差的方式类似于掩码预测。查询 token 和视觉 token 也通过 3 层 MLP 投影,分别表示为
Q
a
t
t
n
∈
R
N
×
256
Q_{attn}∈ℝ^{N×256}
Qattn∈RN×256和
V
a
t
t
n
∈
R
H
/
16
×
W
/
16
×
K
×
256
V_{attn}∈ℝ^{H/16×W/16×K×256}
Vattn∈RH/16×W/16×K×256,其中 K 是 ViT CLIP 模型的注意力头数。通过
Q
a
t
t
n
Q_{attn}
Qattn 和
V
a
t
t
n
V_{attn}
Vattn 的内积,我们得到注意力偏差:
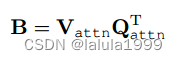
其中 B ∈ R H / 16 × W / 16 × K × N B∈ℝ^{H/16×W/16×K×N} B∈RH/16×W/16×K×N。此外,如果需要,注意力偏差将进一步调整为 B ∈ R h × w × K × N B∈ℝ^{h×w×K×N} B∈Rh×w×K×N,其中 h h h 和 w w w 是 CLIP 中注意力图的高度和宽度。在实践中, Q m a s k Q_{mask} Qmask 和 Q a t t n Q_{attn} Qattn 可以共享,注意力偏差将应用于 CLIP 的多个自注意力层,即偏差在不同的自注意力层中使用。
掩码预测和识别分离设计的动机很直观:CLIP 中识别掩码所用的感兴趣区域可能与掩码区域本身不同。
对视觉 token 的特征融合
ViT 模型由视觉 token 和 [CLS] token 组成,但我们只将视觉 token 融合到 SAN 中。由于 CLIP 和 SAN 的视觉 token 数量和特征维度可能不同,我们首先将视觉 token 重新排列为特征图,经过 1×1 卷积和调整大小操作来调整通道维度和特征图大小,然后通过按元素相加的方式将其与 SAN 对应的特征图合并。特征融合会执行多次,以 12 层 ViT-B/16 CLIP 模型和 8 层 SAN 模型为例,我们将 CLIP 的 { s t e m , 3 , 6 , 9 } \{stem, 3, 6, 9\} {stem,3,6,9}层特征与 SAN 的 { s t e m , 1 , 2 , 3 } \{stem, 1, 2, 3\} {stem,1,2,3}层特征进行融合。
使用注意力偏差进行掩码识别
原始 CLIP 模型只能通过 [CLS] token 进行图像级别的识别。我们的工作在不改变 CLIP 模型参数的情况下,试图通过引导 [CLS] token 的注意力图到感兴趣区域来实现准确的掩码识别。为此,我们创建了一组 [SLS] token 作为 [CLS] token 的影子副本。这些 [SLS] token 单向地由视觉 token 更新,但视觉 token 和 [CLS] token 不受它们的影响(图 4)。
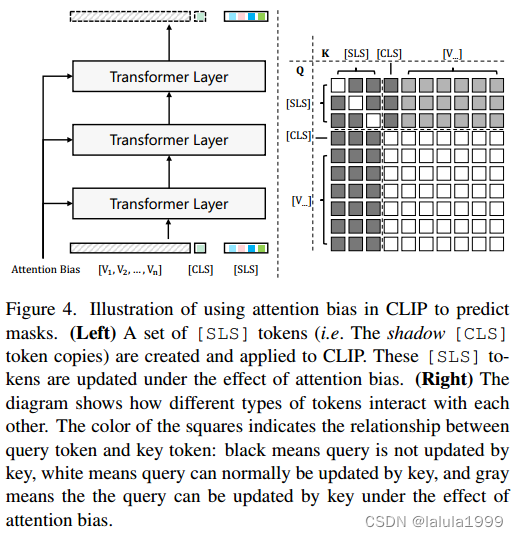
在更新 [SLS] token 时,将预测的注意力偏差
B
k
∈
R
h
×
w
×
N
B_k ∈ℝ^{h×w×N}
Bk∈Rh×w×N 添加到注意力矩阵中:
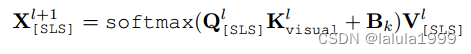
其中
l
l
l 表示层数,
k
k
k 表示第 k 个注意力头。
Q [ S L S ] = W q X [ S L S ] Q_{[SLS]} = W_qX_{[SLS]} Q[SLS]=WqX[SLS] 和 V [ S L S ] = W v X [ S L S ] V_{[SLS]} = W_vX_{[SLS]} V[SLS]=WvX[SLS] 分别是 [SLS] token 的查询和值嵌入, 而 K v i s u a l = W k X v i s u a l K_{visual} = W_kX_{visual} Kvisual=WkXvisual 是视觉 token 的键嵌入。 W q W_q Wq、 W k W_k Wk 和 W v W_v Wv 分别是查询、键和值嵌入层的权重。
我们注意到,如果通过将所有类型的 token 连接在一起并使用掩码自注意力层来实现,计算复杂度为 O ( ( T v i s u a l + T [ C L S ] + T [ S L S ] ) 2 ) O((T_{visual}+T_{[CLS]}+T_{[SLS]}) ^2 ) O((Tvisual+T[CLS]+T[SLS])2),其中 T v i s u a l T_{visual} Tvisual、 T [ C L S ] T_{[CLS]} T[CLS] 和 T [ S L S ] T_{[SLS]} T[SLS] 分别是不同类型 token 的数量。
但是,我们可以通过交叉注意力来更新 [SLS] token,这与自注意力共享嵌入权重。
因此,计算复杂度变为 O ( ( T v i s u a l + T [ C L S ] ) 2 + T [ S L S ] ( T v i s u a l + T [ C L S ] ) ) O((T_{visual}+T_{[CLS]})^ 2 + T_{[SLS]}(T_{visual} + T_{[CLS]})) O((Tvisual+T[CLS])2+T[SLS](Tvisual+T[CLS]))
通过注意力偏差,[SLS] token 的特征逐渐演化以适应掩码预测,可以通过比较 [SLS] token 与类名 CLIP 文本嵌入 P ∈ R C × N P ∈ℝ^{C×N} P∈RC×N 之间的距离/相似度来轻松获得掩码的类别预测,其中 C 是类别数。
分割图像生成
使用掩码提议
M
∈
R
H
/
16
×
W
/
16
×
N
M ∈ℝ^{H/16×W/16×N}
M∈RH/16×W/16×N 和掩码的类别预测
P
∈
R
C
×
N
P ∈ℝ^{C×N}
P∈RC×N,我们可以计算出分割图S:
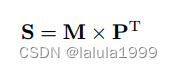
其中 S ∈ R H / 16 × W / 16 × C S ∈ℝ^{H/16×W/16×C} S∈RH/16×W/16×C 。这是语义分割的标准输出,因此与主流的语义分割评估兼容。
为了训练我们的模型,我们遵循[7]的做法。掩码生成受 dice 损失 L m a s k d i c e L_{mask_dice} Lmaskdice 和二元交叉熵损失 L m a s k b c e L_{mask_bce} Lmaskbce 的监督。掩码识别受交叉熵损失 Lcls 的监督。总损失为:
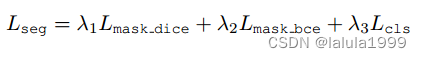
其中损失权重 λ1、λ2、λ3 分别为 5.0、5.0 和 2.0。
SAN 的梯度流如图2所示。通过端到端训练,侧适配器网络可以最大限度地适应冻结的 CLIP 模型,因此掩码提议和注意力偏差都具有 CLIP 感知性。
实验